Customer Relationship Management (CRM)
Data Farm
Inc.®
|
The Technical "Know-How"
|
Data DAO-XML - Thinking Outside the Box
The traditional approach to database, tables, SQL queries are taking a beating when it comes
to Big Data and CRM analysis. Again, we need to think outside the box and not to follow the
very same approach with Hadoop. Sadly Hadoop is nothing more than data filing system that is
designed to store and retrieve Big Data.
XML Data Type - Database Fields:
Can we store and/or retrieve a stream (file of text) of XML file into the database XML field?
The answer is: we can use what is known Character Large Objects (CLOBs) field. It is a stream
of text. We may also use XML data type fields. Not all databases support such fields, but the
one that does, may store data ranging in size from zero bytes to 2 gigabytes.
What can we do with XML Field?:
Before databases exists, developers used text as well as binary files to store data to hard
drives (Persistence). All the search, updates and other functionality were done on these text
or binary files. With the new XML field and database support for handling this type of field, the
query calls to this field would open doors that help eliminate numerous tables and overkill of
fields and redundancies. See the Web Services image for details.
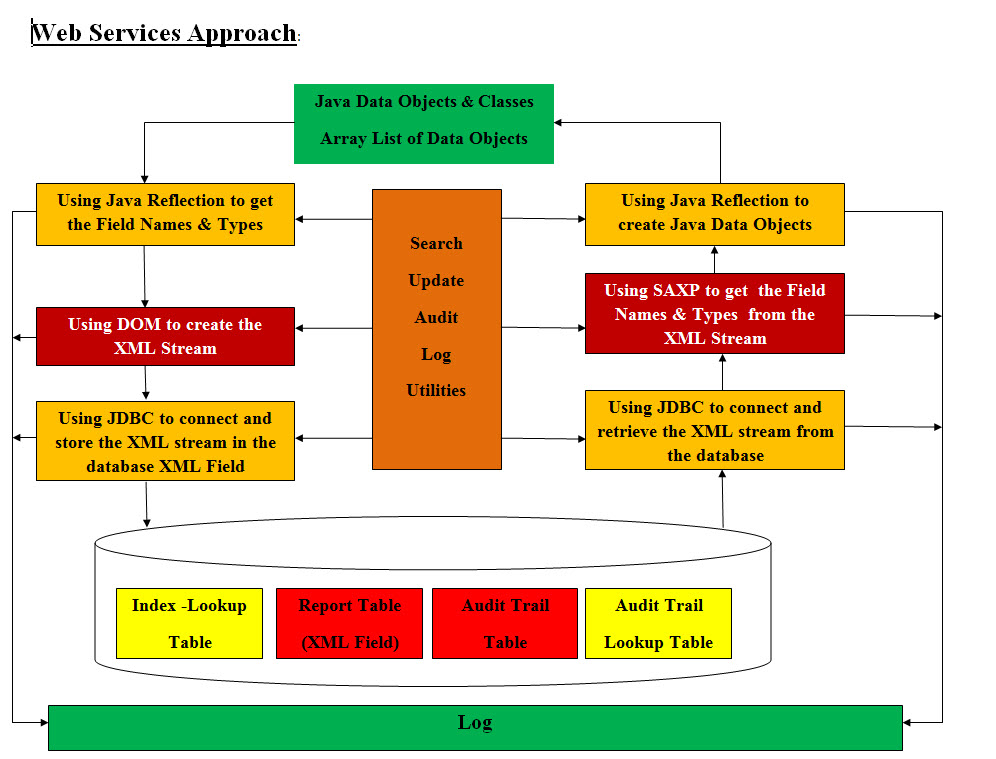
The Normalization and Denormalization of the database table can be another performance concern. Our
approach was to convert the Java data objects into XML stream (text) and store the XML stream into
the database XML data type field. The reverse is very much the way from XML data field to XML stream
and XML stream to Java data objects (DAO). We will be using SAXP, DOM and Java Reflection to perform the
conversion from Java data objects (or even arrays of data objects) to XML files and back with one
easy step. This is very simple and direct, but we need to have our database
tables are as follows:
• Index Table
• Report Table
• Audit trail Table
• Audit trail Index Table
Our approach is to move the data into Java data objects (DAO) in memory for direct processing without any database
processing or conversion (Normalization and Denormalization). We moved the entire processes into Java control
and the database processes and conversion are eliminated to XML retrieval. See the Database Services for
handling the XML editing.
Index Table:
It has record ID, and most of the quick lookup fields and the number of fields should be small.
Report Table:
It has record ID, and the report (XML stream) field.
Audit Trail Table:
It has record ID, audit trail (data and ID), user ID and time stamp fields.
Audit Trail Index Table:
It has record ID, audit trail index, user ID and time stamp fields.
|
|